There is a moment every platform engineer recognizes. It is 3am. You have 87 tenants running in production. Your phone is ringing because one of them can't connect to their database. You open your terminal and realize you have no idea which of the twelve moving parts failed first — was it the Helm deployment, the Terraform provisioning, the certificate, or the secret rotation? You have logs from six different systems and none of them tell the same story.
This article is about building the kind of infrastructure where that moment either never arrives, or when it does, the answer is one command away.
I attended a hands-on workshop on building scalable multi-tenant SaaS platforms on Amazon EKS today, and I want to share not just what I learned mechanically — the Helm charts, the Flux controllers, the Argo Workflows — but the deeper architectural thinking that connects those tools to the compliance, observability, and operational concerns that actually matter when you're running real software for real organizations.
The Problem Nobody Talks About in Architecture Diagrams
Most multi-tenant SaaS architecture diagrams show you the happy path. Tenant onboards, resources provision, traffic routes correctly, everyone goes home. What they omit is the organizational complexity hiding inside every arrow.
Consider a real scenario: a mid-market fintech running a compliance automation platform for their enterprise clients. Each client is a tenant. Each tenant has regulatory obligations — PIPEDA in Canada, SOX for public companies, CMMC for defense contractors. Each regulatory regime requires not just that the software works, but that every change to the infrastructure, every secret accessed, every configuration drift is logged, timestamped, and attributable to a human identity.
Now imagine you have forty of these clients. Now imagine you're onboarding five more next month.
The traditional approach — manually provisioning infrastructure per client, managing secrets through environment variables, applying updates one tenant at a time — works until it doesn't. The failure mode is not spectacular. It's gradual erosion. One client's configuration drifts because someone edited it directly in the AWS console. Another client's certificate expires because the renewal was a manual step. A third client is still running the old version of the compliance agent because the upgrade process requires coordination you haven't had time to do.
This is not a technology problem. It is a systems design problem. And the tools we now have — specifically the combination of GitOps via Flux, Terraform Enterprise with workspace versioning, and Vault 2.0 with workload identity federation — give us a coherent answer to it for the first time.
What GitOps Actually Means in Production
The word GitOps gets used loosely. I want to be specific about what it means in the architecture we built today, because the specificity matters.
In this system, Git is not a deployment trigger. Git is the legal contract between what the platform says it will run and what it actually runs. The Flux reconciliation engine — running continuously inside the Kubernetes cluster — compares the state declared in Git against the actual state of every resource in the cluster. When they diverge, Flux does not send an alert and wait for a human. It fixes the divergence. Automatically. Every time.
Think about what this means in practice for a compliance engineer at a regulated financial institution. Every configuration change is a Git commit. Every Git commit has an author, a timestamp, and a cryptographic hash. The cluster cannot run anything that is not in Git. If a junior engineer or an automated script or a compromised process tries to change the cluster state directly using kubectl apply, Flux will overwrite it on the next reconciliation cycle. The manual change leaves no lasting effect and no ambiguity in the audit trail.
This is what the workshop called the immutability firewall, and it is more powerful than it sounds. It means the cluster's compliance posture cannot drift silently. It means when an auditor asks "what was running in the tenant-7 namespace at 2pm on the fourteenth," you can answer that question from Git history alone, without requiring logs from the cluster itself.
The Three Tiers That Map to Every SaaS Business Model
One of the most practically useful things I learned today was that the tier strategy of a SaaS platform — basic, advanced, premium — is not a pricing decision that gets implemented after the architecture is built. It is an architectural decision that should shape the infrastructure from day one, because the cost, isolation, and compliance profile of each tier are fundamentally different.
Here is how the tiers map to real business logic using a single Kubernetes cluster.
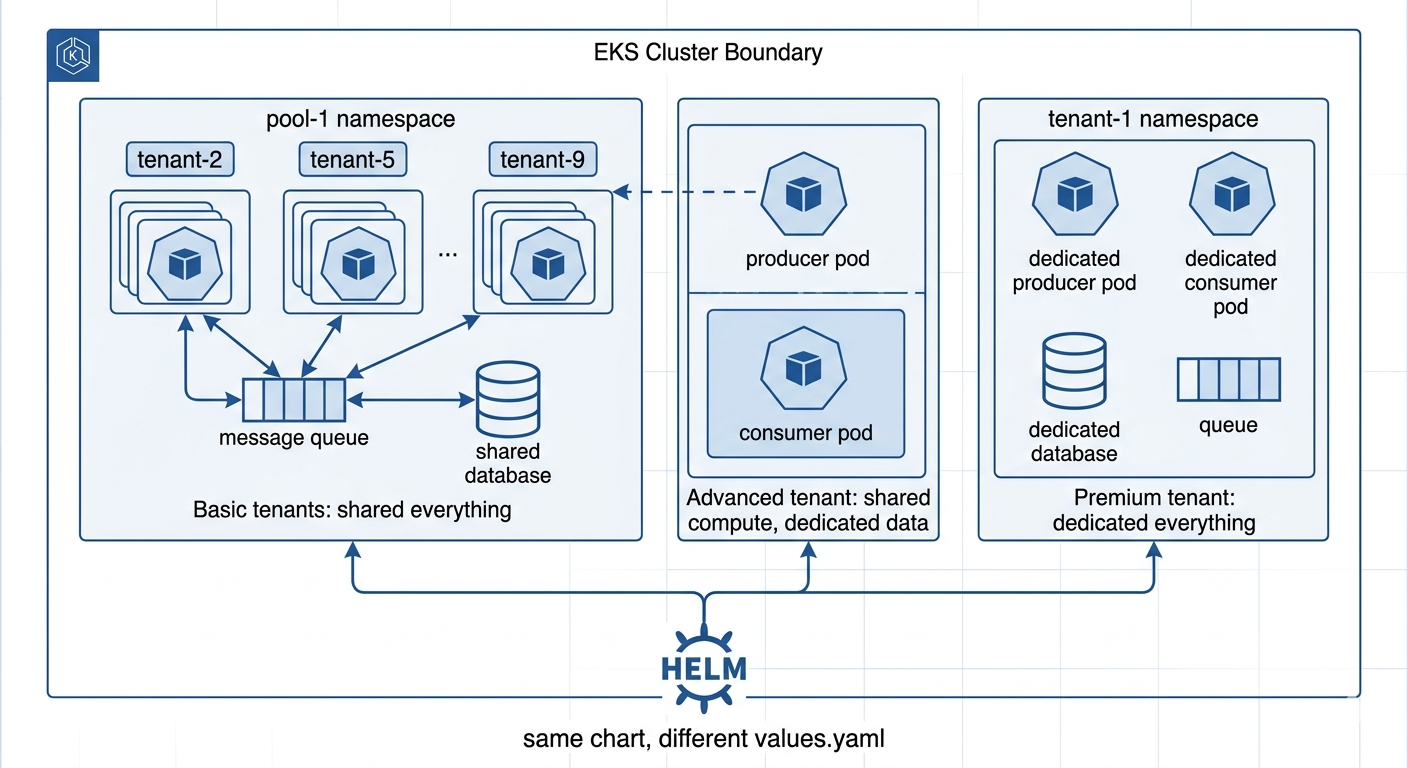
A basic tier tenant shares compute and storage with other basic tier tenants. Their application runs in a shared pool namespace. Their requests are routed to the right namespace by an HTTP header carrying their tenant identifier. They share a message queue and a database cluster with their neighbors. The cost of serving them is low because the infrastructure cost is amortized across many tenants. The risk is the noisy neighbor problem — one tenant's heavy workload degrades everyone else's experience.
A premium tier tenant has a dedicated Kubernetes namespace. Their application pods run on nodes they do not share. Their database table and message queue are provisioned exclusively for them. They can never affect another tenant's performance and cannot be affected by another tenant's performance. The cost of serving them is higher, but the isolation is complete.
An advanced tier tenant lives in the middle. Their compute is split: the component that handles read-heavy, stateless work runs in the shared pool. The component that handles stateful, sensitive work runs in a dedicated namespace. This hybrid model is common in real enterprise SaaS — it reflects the reality that not all parts of an application have the same compliance requirements, and you should only pay for isolation where isolation genuinely matters.
What makes this elegant from an engineering perspective is that all three tiers are served by the same Helm chart. The tier configuration is entirely in a values file — a few lines of YAML that declare which components are enabled and whether they run in dedicated or shared namespaces. Adding a new tier requires creating a new template file, not changing the chart itself. The infrastructure follows the business model, not the other way around.
The Automation Chain Nobody Shows You End to End
Here is something the architecture diagrams get wrong by omission. They show you the components — Argo Workflows, Flux, Terraform, Helm — but they don't show you the handoffs between them, and those handoffs are where the real engineering decisions live.
Let me walk you through what actually happens when a new enterprise client signs up for your SaaS platform and needs to be onboarded.
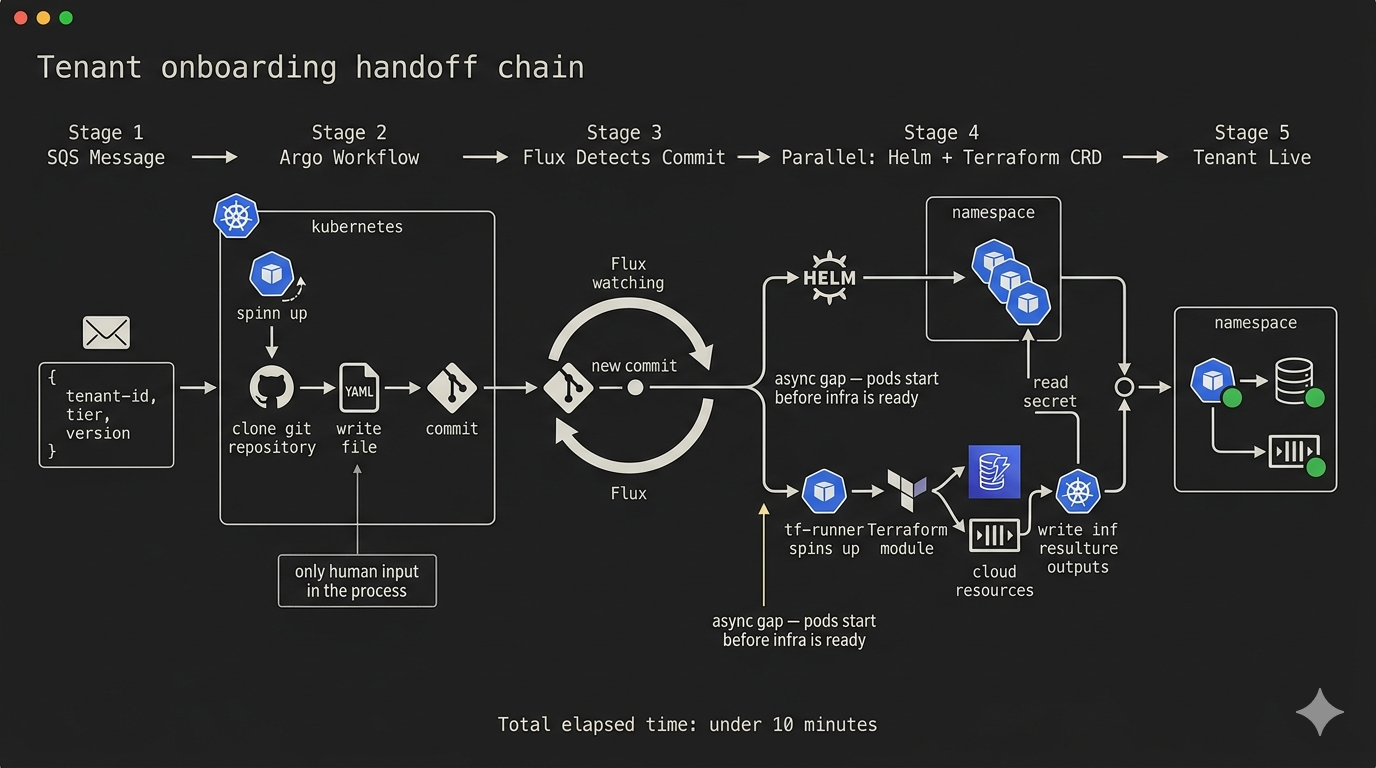
An event arrives. In our architecture, this is an SQS message containing three pieces of information: the client's identifier, the tier they've purchased, and the version of the platform they should receive. This message is the only human input in the entire provisioning process.
Argo Events, a Kubernetes-native event listener, picks up the message and triggers an Argo Workflow. The workflow is a sequence of steps — not manual steps, but automated ones executed by pods that spin up and terminate within the cluster. The workflow does one thing: it clones the GitOps repository, generates the correct Helm release YAML for the new tenant based on their tier template, commits that file to the repository, and pushes. Then it exits.
That is all Argo Workflows does. It does not deploy to Kubernetes. It does not provision AWS resources. It writes a file to Git and goes home.
From that point forward, Flux takes over. Flux detects the new commit. It reconciles the new HelmRelease manifest. Helm deploys the application workloads into the tenant's namespace. Simultaneously, the Helm chart contains an embedded Terraform CRD — a custom Kubernetes resource that tells the Tofu controller to provision the tenant's AWS infrastructure: a DynamoDB table for their data, an SQS queue for their messages, an IAM role scoped to exactly the permissions their application needs.
The Tofu controller spins up a short-lived pod, pulls the Terraform module from a pinned Git tag, runs the plan and apply, and when it completes, writes the infrastructure outputs — queue URL, table name, role ARN — into a Kubernetes secret scoped to the tenant's namespace.
The application pods, which have been starting concurrently, detect the secret's arrival and complete their initialization sequence.
The tenant is live. From SQS message to running application: fully automated, fully auditable, zero manual steps.
Where Terraform and Vault 2.0 Change the Compliance Story
I want to be precise here, because the marketing language around these products is often vague in ways that obscure what is genuinely useful.
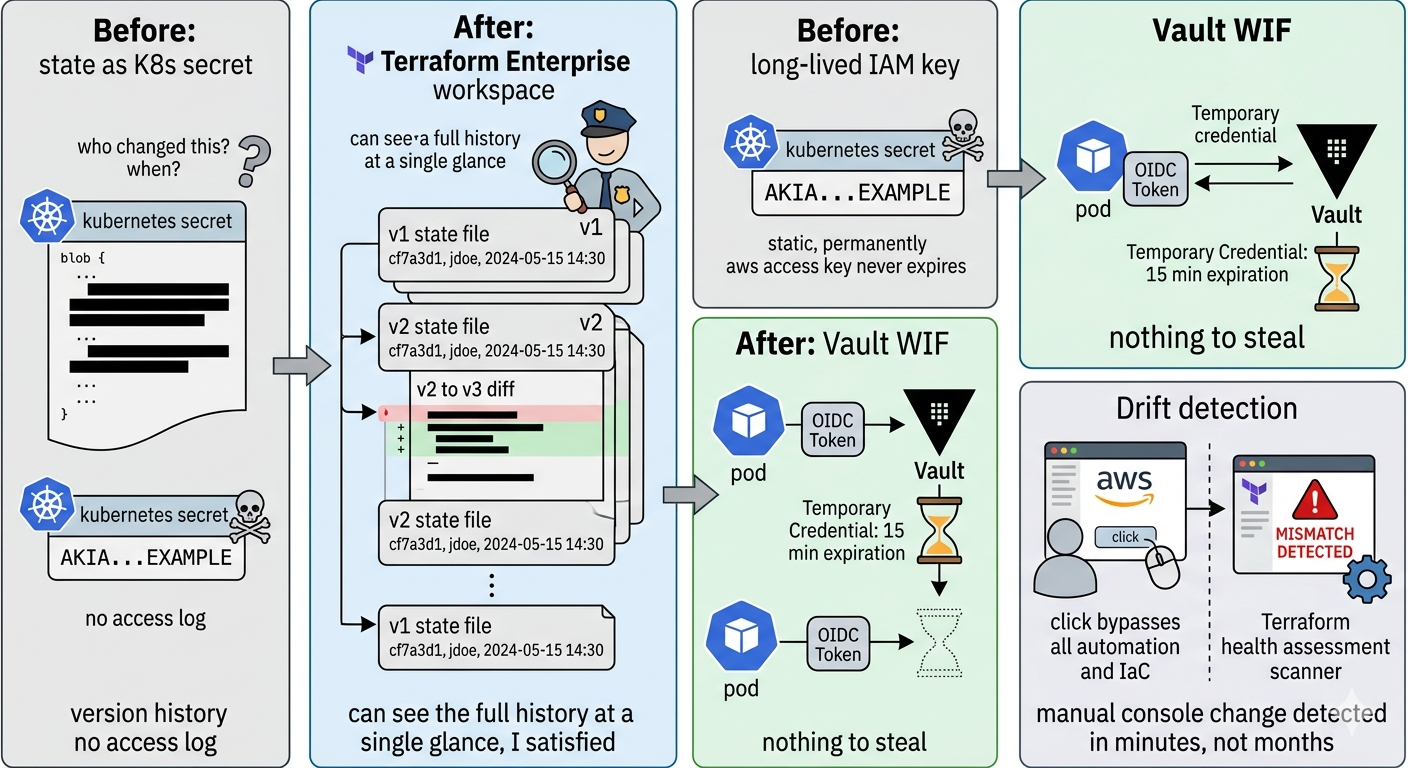
The open-source Tofu controller we used in the workshop stores Terraform state as a Kubernetes secret. This is functional but not audit-grade. The state file contains infrastructure identifiers, configuration values, and sometimes credentials. It sits in the cluster as an opaque blob with no versioning, no diff history, and no access logging.
Terraform changes this in three ways that matter for regulated environments.
First, every workspace maintains a complete version history of its state file. Every apply creates a new state version linked to the VCS commit and the user or service account that triggered the run. When an auditor asks what the database configuration looked like on a specific date for a specific tenant, the answer is a click away in the Terraform UI, with a diff showing exactly what changed and who authorized it.
Second, Terraform's health assessments run drift detection continuously. If someone changes a database configuration directly in the AWS console — bypassing the automation entirely — Terraform detects the discrepancy between the declared state and the actual state and raises an alert. This closes the most common compliance gap in infrastructure management: the manual console change that nobody logged.
Third, workspace run triggers allow you to sequence infrastructure provisioning. The network workspace must complete before the database workspace begins. The database workspace must complete before the application workspace begins. This is the answer to the async gap we identified in the workshop — the race condition where application pods start before their infrastructure exists. With workspace run triggers, the sequencing is enforced by the platform, not by init container sleep loops.
Vault 2.0 closes a different but equally critical gap: the credential surface.
In the workshop architecture, the tf-runner pod needed AWS credentials to provision resources. In a naïve implementation, those credentials are long-lived IAM keys stored as Kubernetes secrets — a significant attack surface. Vault 2.0's workload identity federation eliminates this entirely. The tf-runner pod authenticates to Vault using an OIDC token generated from its Kubernetes service account. Vault validates the token against the Kubernetes OIDC endpoint and returns a short-lived AWS credential scoped to exactly the permissions the run requires. When the run completes, the credential expires. There is nothing to steal.
The same model applies to the application pods. Each tenant's consumer and producer services authenticate to Vault using their service account OIDC tokens. Vault returns short-lived credentials scoped to that specific tenant's DynamoDB table and SQS queue. A compromised pod can only access its own tenant's data, and only for the duration of its current credential window.
Vault's audit device logs every one of these authentications — the identity, the requested path, the returned credential, the timestamp. For a compliance officer, this is the chain of custody for every data access event in the system.
The Real-World Translation: What This Means for Companies Building on This Stack
Let me ground this in three real scenarios that this architecture directly addresses.
Scenario One: The Compliance Automation Platform
A company builds software that helps enterprises manage their compliance obligations — document collection, evidence mapping, audit trail generation. Each enterprise client is a tenant. Each tenant's compliance documents are sensitive and must not be accessible to any other tenant under any circumstances.
The hybrid tier model maps cleanly here. The ingestion pipeline — collecting and processing documents — can run in a shared pool because it handles only encrypted payloads and has no direct access to the decrypted content. The storage and retrieval layer — where the actual compliance documents live and where audit queries run — must be siloed, with dedicated storage per tenant, dedicated IAM roles scoped to that tenant's data, and Vault policies that make cross-tenant access cryptographically impossible rather than just logically prevented.
When a new enterprise client signs up, the onboarding workflow provisions not just the application namespace but the entire compliance infrastructure: the dedicated S3 bucket with server-side encryption using a KMS key scoped to that client, the DynamoDB table for the audit trail, the Vault policy that restricts read access to workloads bearing that specific client's workload identity. All of this is automated, all of it is declared in Git, and all of it is auditable to the individual commit and the individual credential access.
When the client leaves or requests data deletion, the offboarding workflow runs the inverse. Vault revokes the client's lease immediately — access is cryptographically terminated before the physical infrastructure is even scheduled for deletion. The timestamp of that revocation is in Vault's immutable audit log. The physical deletion follows asynchronously, and its completion is recorded in Terraform's run history.
Scenario Two: The B2B SaaS Platform with Enterprise and SMB Customers
A company offers a business intelligence platform. Their SMB customers don't need dedicated infrastructure — the pool model is more than sufficient, and the cost savings allow competitive pricing. Their enterprise customers have procurement requirements mandating dedicated compute, specific data residency, and the ability to produce evidence of isolation for their own auditors.
The three-tier model handles this without architectural divergence. The same Helm chart, the same Terraform modules, the same deployment pipeline serve both segments. The difference is in the values file that configures the Helm release and the workspace configuration in Terraform. SMB customers map to the basic tier template. Enterprise customers map to the premium tier template. A growing mid-market customer who starts on basic and upgrades to premium is a configuration change in Git — a new values file, a new commit, a Flux reconciliation that spins up their dedicated resources while Argo Workflows deprovisions their pool-based routing.
The business impact: the platform team does not need to maintain separate codebases or separate deployment pipelines for their two customer segments. They maintain one. The complexity of serving two fundamentally different infrastructure models is absorbed by the tier template system, not by additional engineering headcount.
Scenario Three: The Regulated Financial Services Platform
A fintech is building a payments infrastructure platform for regional banks. Each bank is a tenant. Each bank is subject to regulatory examination. The regulator wants to see evidence that the bank's data cannot leak to another bank, that every infrastructure change was authorized, and that credentials are rotated on a defined schedule.
This is where the combination of all three audit layers becomes essential.
Terraform provides the infrastructure change evidence: every modification to a bank's provisioned resources is a versioned state change linked to an authorized Git commit. The regulator can see the full history of every DynamoDB configuration change, every IAM policy modification, every network rule addition, with the author and timestamp of the Git commit that authorized it.
Vault provides the credential access evidence: every time the bank's application accessed a sensitive secret or received a dynamically generated AWS credential, that access is in Vault's immutable audit log with the workload identity that requested it. Credential rotation happens on a schedule defined in Vault policy, not in a calendar reminder, and the rotation events are logged.
Flux provides the runtime configuration evidence: the Kubernetes state that was actually running at any point in time is recoverable from Git history. The immutability firewall means the audited state and the declared state are the same, provably and continuously.
Three systems, three layers, one coherent answer to the question every financial regulator asks first: how do you know what was running, who authorized it, and who had access to the sensitive data?
The Question That Remains: Scale and the Queue
I want to be honest about what this architecture does not solve, because intellectual honesty is more useful to you than comprehensive optimism.
The Flux reconciliation queue is still a single-controller bottleneck. At 87 tenants, the helm-controller processes HelmRelease objects sequentially. A slow Terraform provisioning that causes a HelmRelease to stay in an unknown state for four minutes delays the reconciliation of every tenant behind it in the queue. At 87 tenants this is an occasional annoyance. At 870 tenants it is a systemic problem.
The answer — running separate Flux controller instances per tier with label selectors so premium tenant reconciliation never shares a queue with basic tenant reconciliation — is available and implementable today. But it requires deliberate architectural effort. It does not come for free with any of the tools we discussed.
Similarly, the Argo Workflows bot commit — the auto-generated YAML that gets pushed directly to the main branch without human review — remains a compliance gap in regulated environments. Terraform can validate a Terraform plan before it applies. Vault can log who triggered the workflow. But neither can intercept and validate the content of a YAML file before it enters the GitOps pipeline. That gap requires an admission webhook — Kyverno or OPA Gatekeeper — sitting between the Git commit and the Flux reconciliation, validating the schema, the security policy, and the authorization before any of it touches the cluster.
These are not criticisms of the tools. They are honest mappings of where the tools end and where deliberate architecture begins.
Designing Enforcement Out of the System
I want to close with something that is not about tools at all.
The pattern connecting everything I described today is the externalization of enforcement. In traditional infrastructure management, compliance is enforced by people — by processes, by checklists, by the hope that the person running the deployment remembers to follow the runbook. This works at small scale and fails at large scale, not because people become less careful, but because the surface area grows faster than the attention available to cover it.
GitOps, workspace versioning, workload identity, and dynamic secrets are all instances of the same principle: encoding the compliance requirement into the system itself so that the system cannot not comply. Flux's immutability firewall doesn't ask anyone to remember not to use kubectl apply in production. It makes the action irrelevant. Vault's short-lived credentials don't ask the developer to remember to rotate their keys. There is nothing to rotate. Terraform's drift detection doesn't ask the operator to check whether the AWS console was used inappropriately. It checks continuously and automatically.
When looking at a system like this, the goal is not to evaluate whether the tools are impressive — they are — but to identify where the human enforcement still lives and to design it out of the system wherever the cost of doing so is less than the cost of the failure mode it prevents.
Today's workshop gave me three new places to look for that work. The Argo Workflows commit path, the Flux controller queue at scale, and the connection between the Vault audit device and the Git audit trail are three seams where human judgment is still load-bearing. Each of them is an engineering problem with a known solution. That is, honestly, the best position to be in.